As you have seen, my recent posts have been around Intel Optane and the performance gains that can be delivered by implementing the technology into a vSAN environment. I have been asked many times about what benefits a full NVMe solution would bring and what such a solution would look like, but before we go into that, let’s talk about NVMe, what exactly is NVMe?
Non-Volatile Memory Express (NVMe) is not a drive type, but more of an interface and protocol solution that looks like is set to replace the SAS/SATA interface. It encompasses a PCIe controller and the whole purpose of NVMe is to exploit the parallelism that flash media provides which in turn reduces the I/O overhead and thus improve performance. As SSDs become faster, protocols like SAS/SATA which were designed for slower hard disks where the delay between the CPU request and data transfer was much higher, the requirement for faster protocols become evident, and this is where NVMe comes into play.
So in a vSAN environment, what does a full NVMe solution look like? Because vSAN is currently a two tier architecture (Cache and Capacity) a full NVMe solution would mean that both tiers have to have NVMe capable drives and this can be done with either all Standard NVMe drives in both cache and capacity, or using a technology like Intel Optane NVMe as the Cache and Standard NVMe as capacity. So from an architecture perspective it is pretty straight forward, but how does performance compare, for this I persuaded my contacts at Intel to provide me some Full NVMe kit in order to perform some benchmark tests, and in order to provide a like for like comparison, I ran the same benchmark tests on an Optane+SATA configuration.
Cluster Specification:
Number of Nodes: 4
Network: 2x 10gbit in LACP configuration
Disk groups per node: 2
Cache Tier both clusters: 2x Intel Optane 375GB P4800X PCIe Add In Card
Capacity Tier Optane/SATA: 8x 3.84TB SATA S4510 2.5″
Capacity Tier Full NVMe: 8x 2.0TB NVMe P4510 2.5″ U.2
Test Plan:
Block Size: 4K, 8K, 16K, 32K, 64K, 128K
I/O Pattern: Random
Read/Write Ratio: 0/100, 30/70, 70/30, 100/0
Number of VMs: 120
Number of VMDKs per VM: 1
Size of VMDK: 50GB
Storage Policy: FTT=1, RAID1
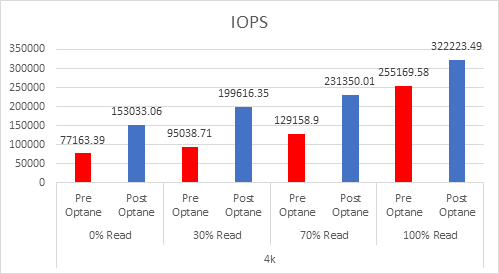
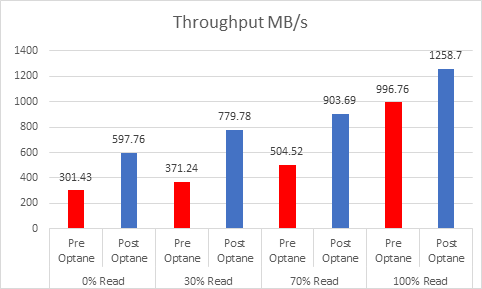
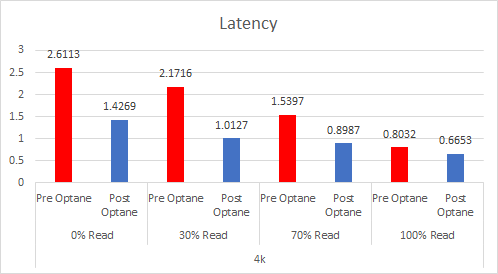
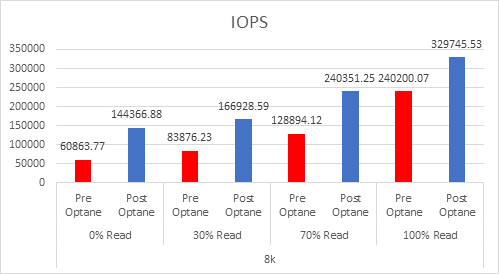
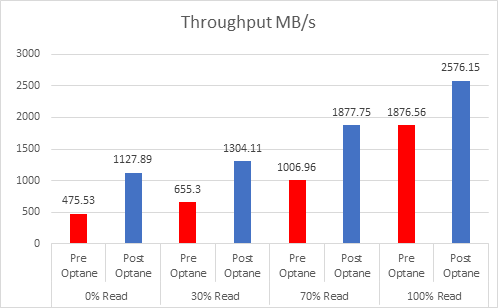
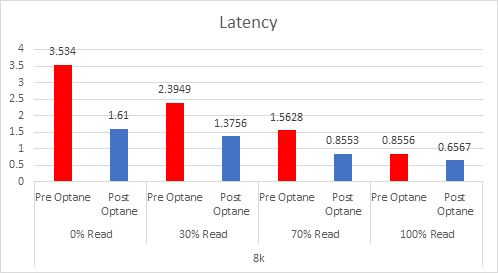
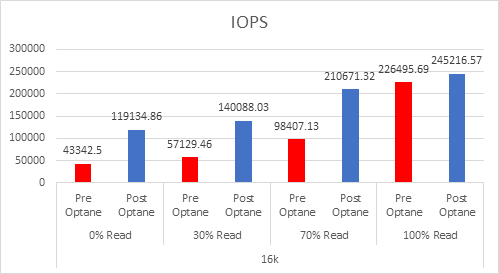
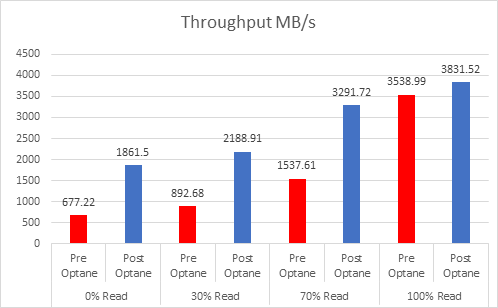
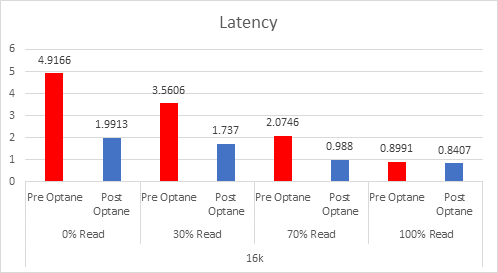
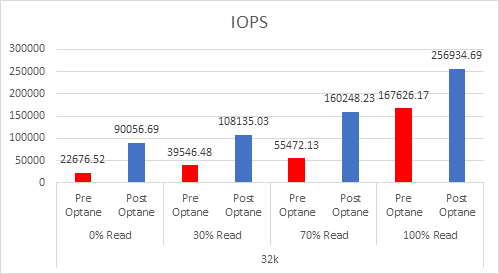
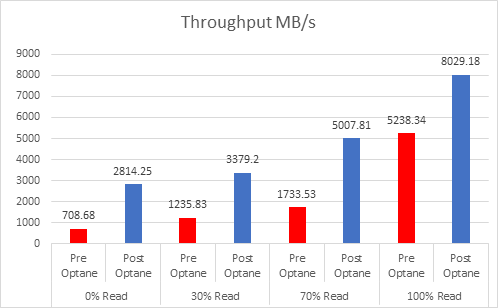
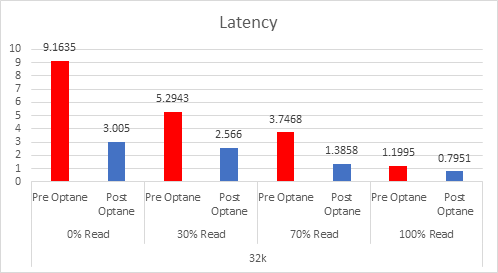
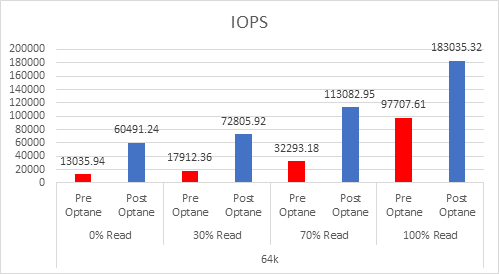
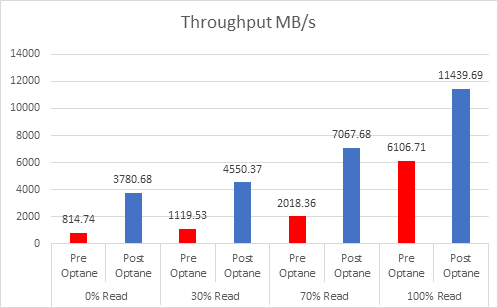
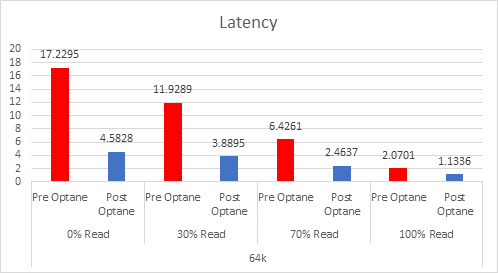
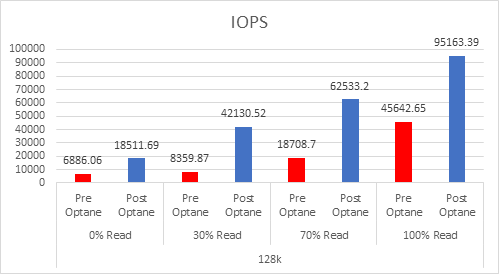
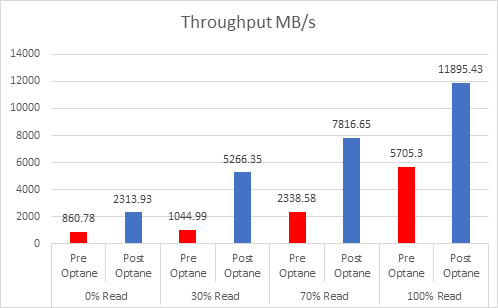
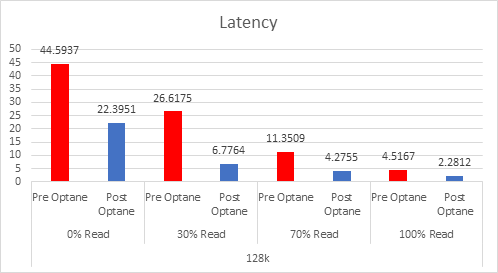
Let’s look at the results:
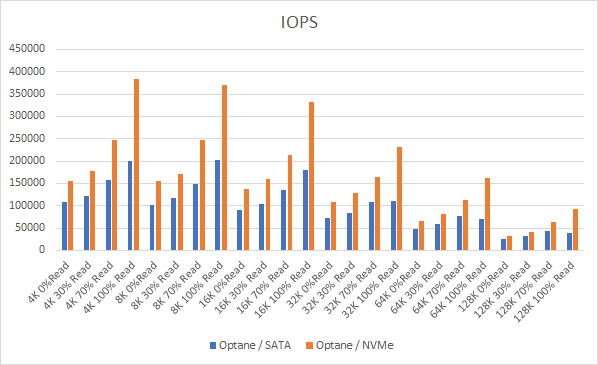
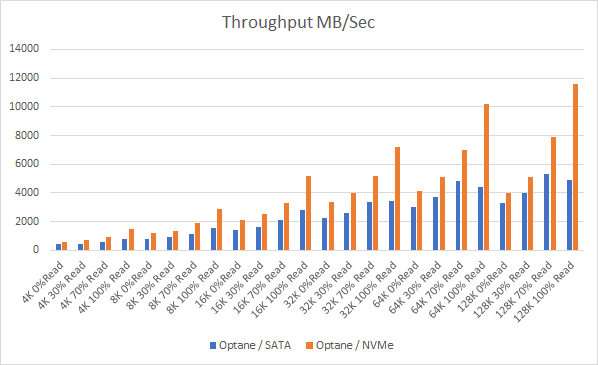
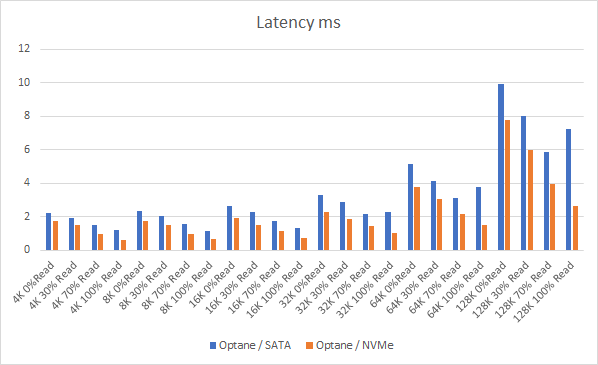
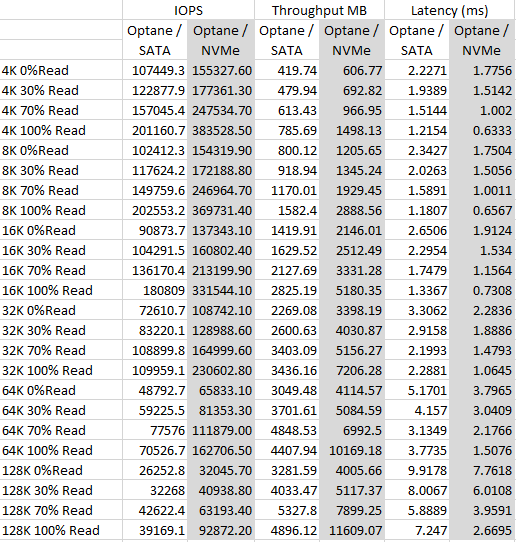
And if you want the numbers:
So what is clear here that Optane serves really well in the cache tier in both solutions, however in the Full NVMe solution read performance is significantly improved also, in the 128K, 100% read test the 2x10G Links were being pushed to their limits, but not only was we able to push up throughput and IOPS but we also drove down latency, in some cases reducing it by over 50%.
So why would you choose a full NVMe solution? The simple answer here is if you have applications that are latency sensitive then having clusters dedicated to those applications would be adequately provided for from an IOPS, Throughput and Latency perspective with Full NVMe.
Vendors have also recognised this, for example Dell EMC have just launched their Intel Optane Powered Full NVMe vSAN Ready node, based on the R740xd platform and consists of similar drives to what I have used in the tests here being the Optane 375GB and P4510 U.2 NVMe drives, you can see the vSAN ready node details here
So clearly NVMe has major performance benefits over traditional SAS/SATA devices, could this be the end of SAS/SATA in the not so distant future?