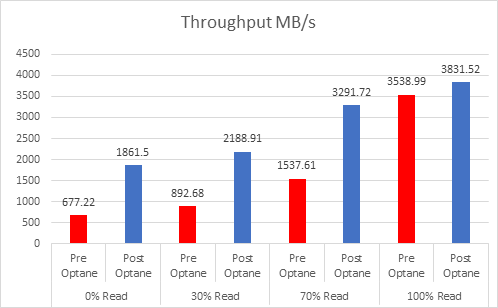
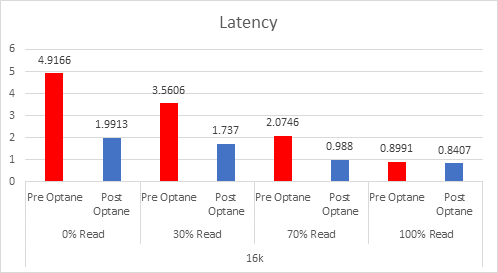
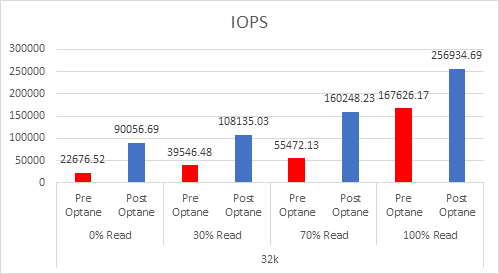
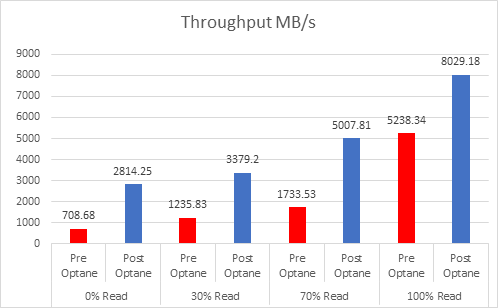
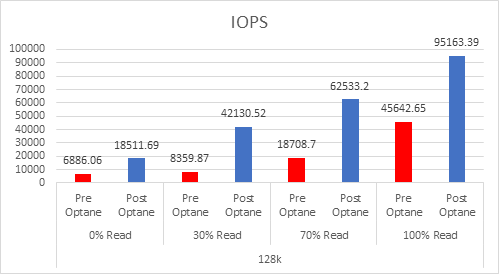
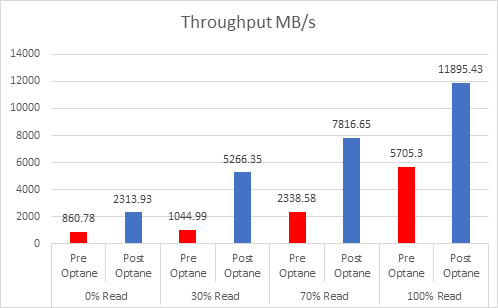
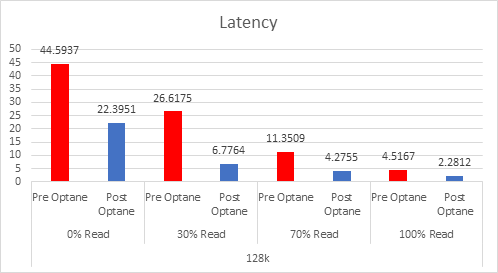
Even since VMware published this article on cache sizing guidelines for all-flash I still get asked two questions, the first one is around the amount of cache required per node? The second is about when vSAN will have a larger write buffer?
The amount of cache required per node in all-flash is not dependant on the amount of usable space like it was in Hybrid configurations, the amount of cache per node is based purely on the endurance of the cache SSDs, which typically fall into four categories:
- Up to 2 drive writes per day
- 3 drive writes per day
- 10 drive writes per day
- 30 drive writes per day
With the birth of the P5800X from Intel having an endurance capability of 100 drive writes per day, I would expect a 5th category will appear soon too.
If we look at the amount of DWPD a drive is capable of we can see whether it would be good in a cache tier or not, for example a device with 0.4-2 DWPD is likely to be certified for the vSAN capacity tier and not the cache tier.
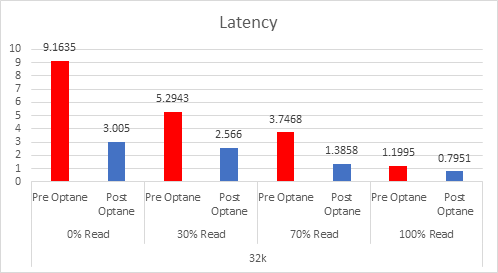
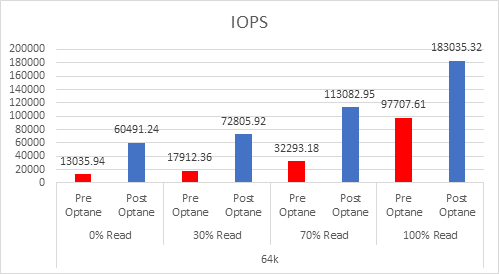
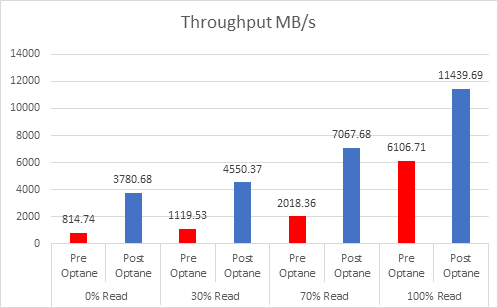
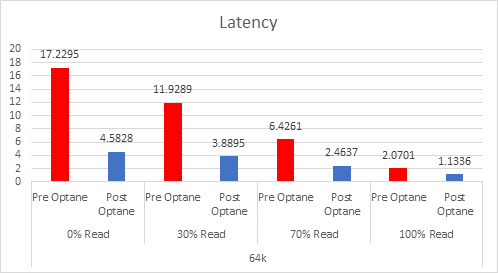
Since the cache tier is where 100% of the writes happen, this is where you need the higher endurance devices, the higher the writes in your environment means you need to look at the endurance as this will be the biggest factor in the amount of cache you need.
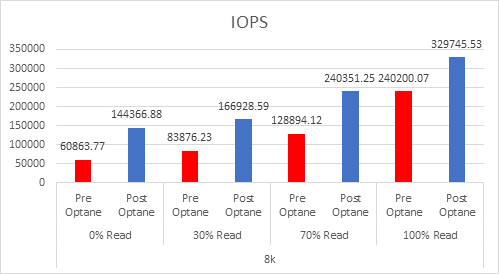
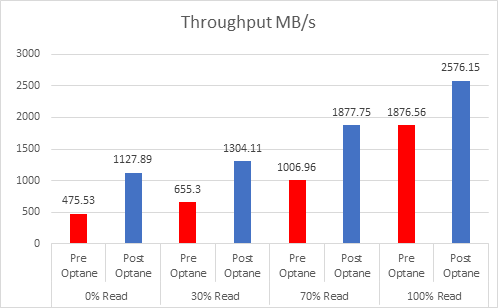
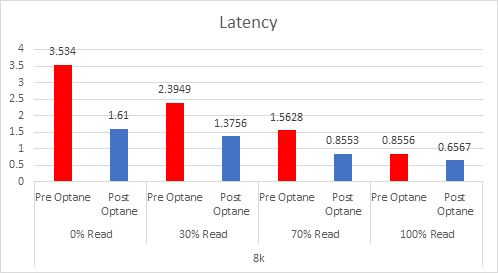
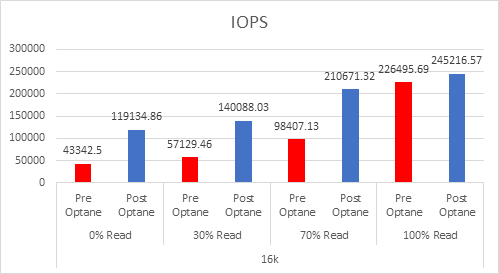
If we look at the 3 DWPD category, this is normally categorised by the vendors as “Mixed-Use”, and is the most economically priced cache device for vSAN, but because of the lower endurance, you actually need more cache. I have looked at a lot of Live Optics reports over the past few months to gather information on what is the average % of writes in a customer environment, and the number that came out was 37%, yes higher than the 30% normally envisaged.
So based on 3DWPD and >30% Random Writes, the VMware Article states you need 3.6TB of cache per node based on an AF-8 Config, so this would result in a likely configuration of 3x 1.6TB Devices:
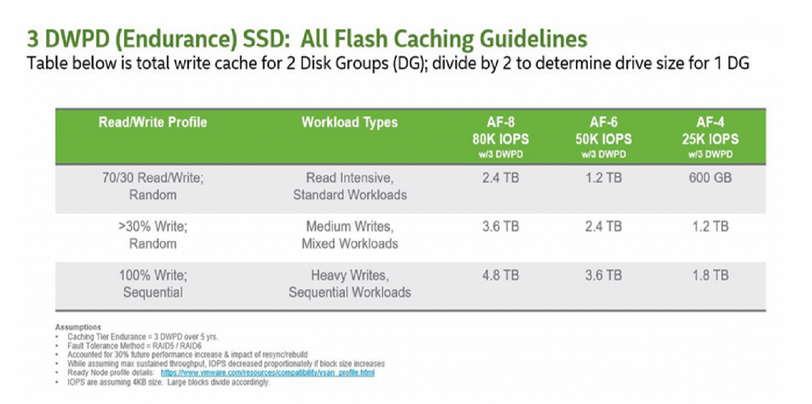
The next category of 10 DWPD, these are usually classed as “Write Intensive” by the vendors, again according to the VMware table you would need 1.2TB of cache per node, again based on an AF-8 Config with >30% Random writes:
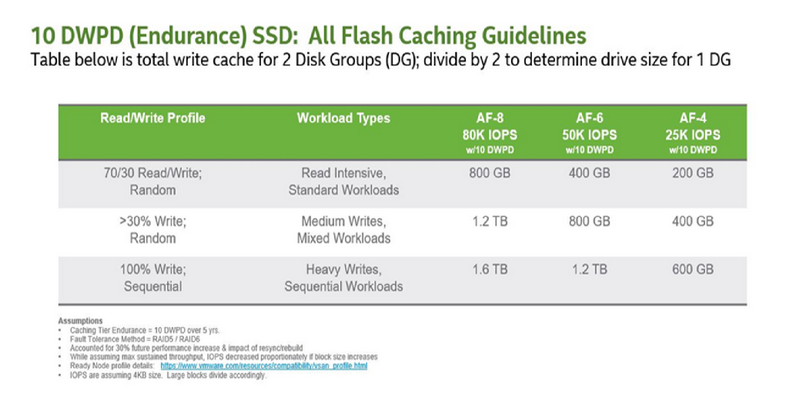
Then we come to the final category of 30 DWPD, these devices are usually categorised as “Write Intensive Express Flash”, and this is usually Intel Optane SSD Devices such as the P4800X, for the same workload, the VMware recommendation is to have 400GB of cache per node:
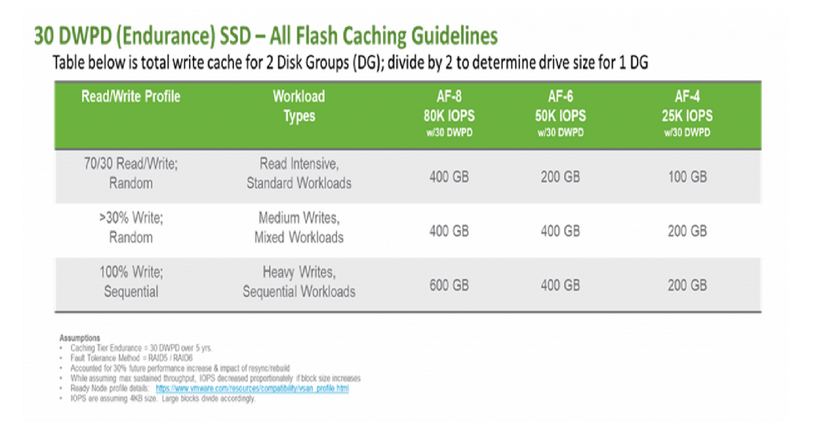
As you can see, the amount of cache you require is based on the endurance of the devices when it comes to vSAN all-flash.
To address the second question about vSAN ever having a larger write buffer, this has been mentioned for a long time, but my opinion here is that you do not need to have a larger write buffer if you are using high endurance devices, and with the new Intel P5800X having an endurance factor of 100 DWPD, I expect that the amount of cache per node would be lower still, so I would not expect a big emphasis on the write buffer from a vSAN perspective.
As SSDs become faster, more higher endurance, it mitigates the need to have larger write buffers, especially in Full NVMe configurations for example where the storage is sat on the PCIe BUS directly, rather than sat behind a disk controller. And in my experience with Intel Optane SSDs, the 375GB (P4800X) and 400GB (P5800X) serve very well even in write intensive environments.