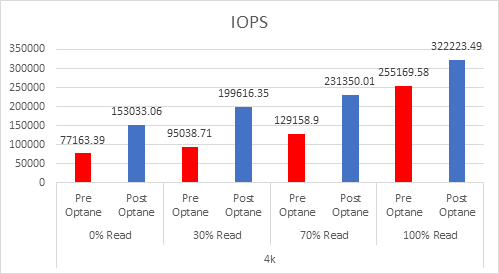
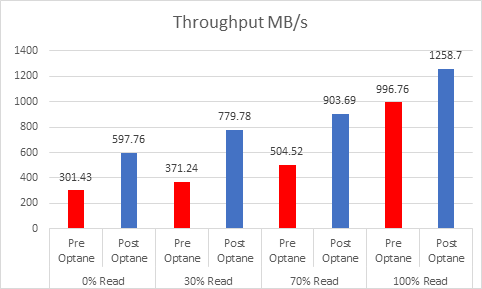
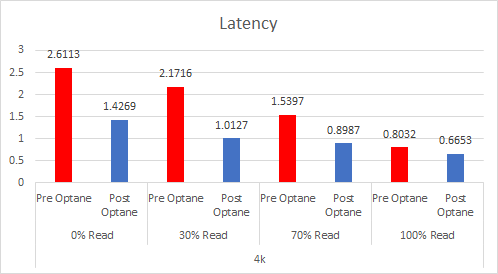
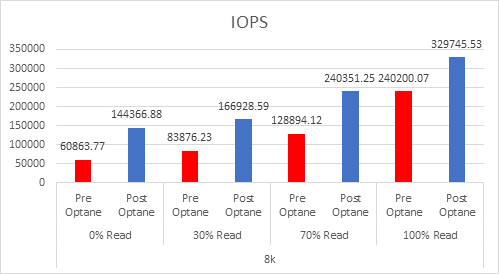
I have done a lot of testing on Optane SSDs in the past, but in July of 2022 Intel announced their intention to wind down the Optane business. Since that announcement I have had many questions surrounding Optane and where it leaves customers today.
Well firstly, I am going to address the messaging that was announced back in July, on the Intel earnings call it was announced that Optane had been written off with over half a billion dollars. This led to quite a storm of confusion as I was asked by many “Does this mean I cannot buy Optane any more?”
To the contrary, Optane is still a product and will continue to be a product until at least the end of 2025, and even if you buy it on the last day it is available, you will still get a 5 year warranty.
I have never really spoken about the other side of the Optane house on this blog before, moreso because it wasn’t directly relevant to vSAN. However, there are two sides to Optane, of course as you know the SSD, but there is also the persistent memory side of the Optane Technology.
Optane Persistent Memory (PMEM) is primarily used in VMware as a memory tiering solution. Over the past few years DRAM has become expensive, as well as having the inability to scale. Memory tiering allows customers to overcome both of the challenges on cost as well as large capacity memory modules. PMEM for example is available in 128GB, 256GB and 512GB modules, at a fraction of the cost of the same size modules of DRAM.

Memory tiering is very much like the Original Storage Architecture in vSAN, you have an expensive cache tier, and a less expensive capacity tier. Allowing you to deliver a higher memory capacity with a much improved TCO/ROI. Below are the typical configurations prior to vSphere 7.0U3.
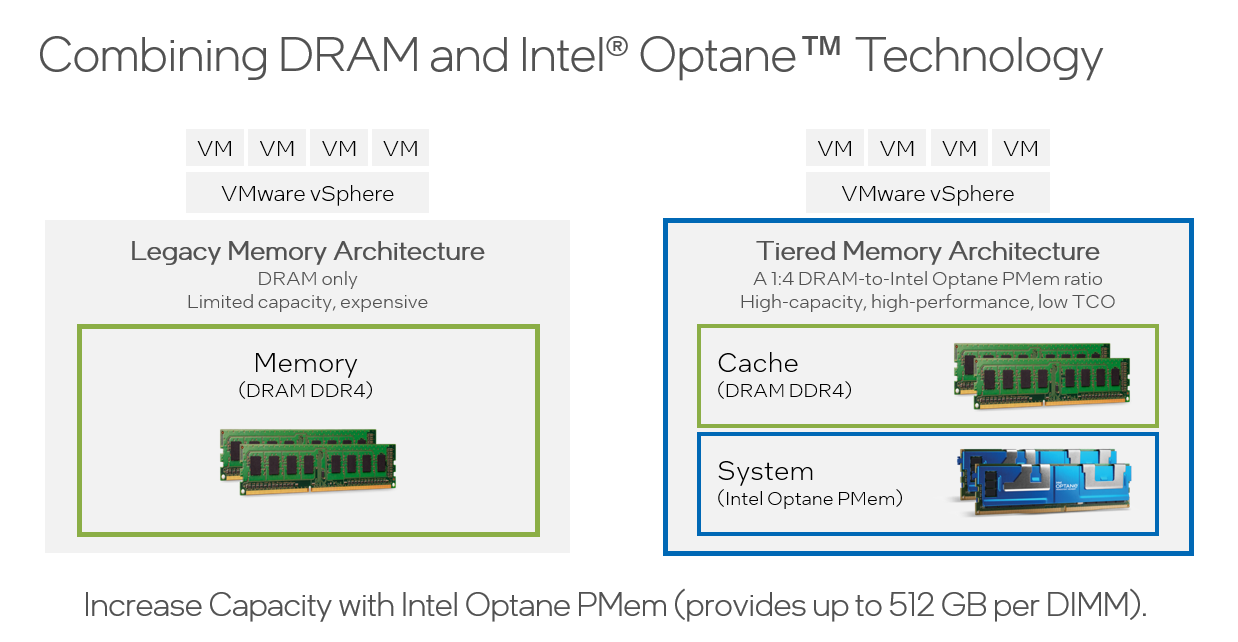

On the horizon we have a new architecture called Compute Express Link (CXL), and CXL 2.0 will deliver a plethora of memory tiering devices. However, CXL 2.0 is a few years away, so the only memory tiering solution out there for the masses is Intel Optane. This is how it looks today and how it may look with CXL 2.0:
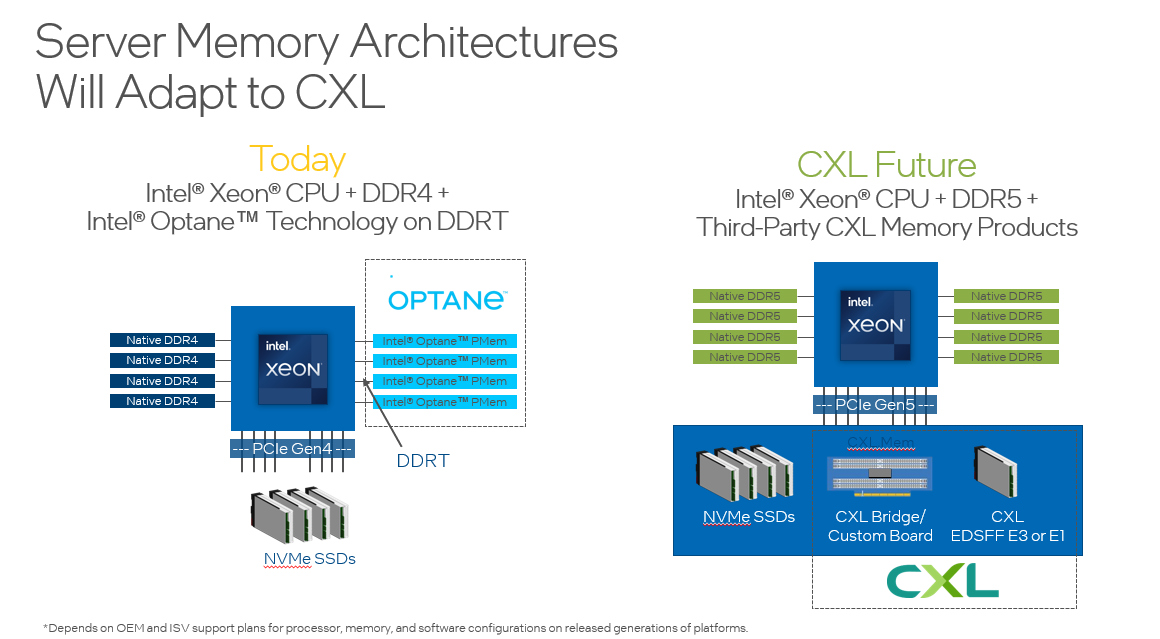
I recently presented at the VMUG in Warsaw where I had a slide that states Ford are discontinuing the Fiesta in June 2023, does this mean you do not go and buy one of these cars today? The simple answer is just because it is going away in the future, it still meets the needs of today. It is the same with Optane Technology, arguably it is around for longer than the Ford Fiesta, but it meets the needs to reduce costs today as a bridge to memory tiering architectures of the future with CXL 2.0.
I like to challenge the status quo, so I challenge you to look at your vSphere, vSAN or VCF environments and look at two key metrics. The first one is “Consumed Memory” and the second one is “Active Memory”. If you divide Consumed by Active and the number you get is higher then 4, then memory tiering is a perfect fit for your environment, and not only can you save a lot of your memory cost, but it also allows you to push up your CPU core count because it is a more affordable technology.

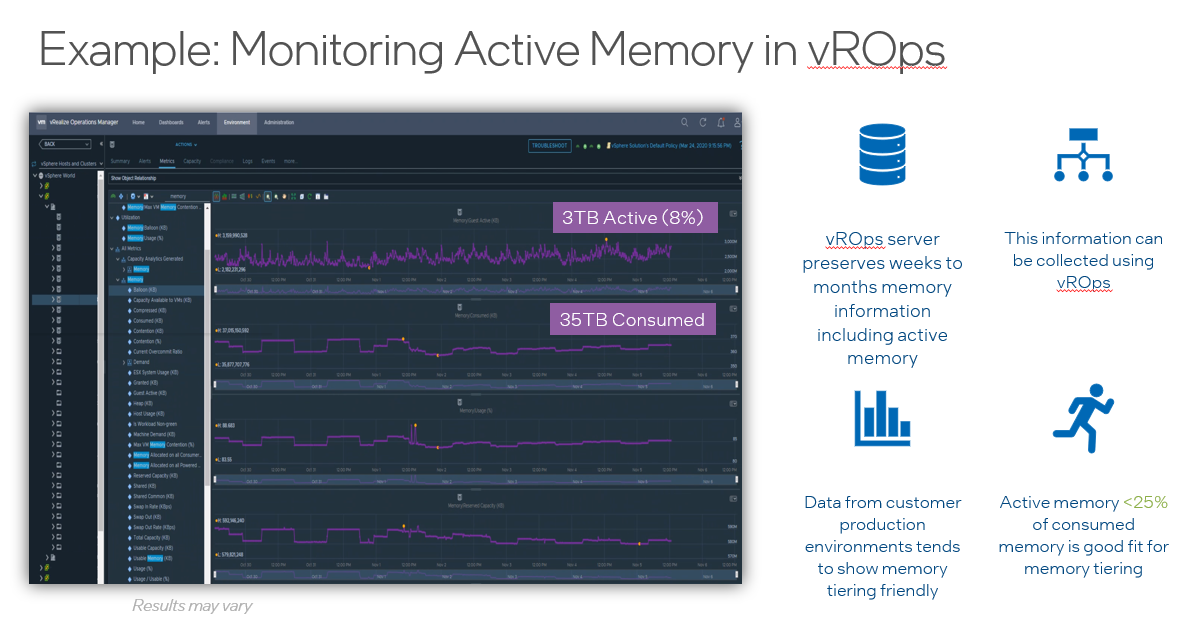
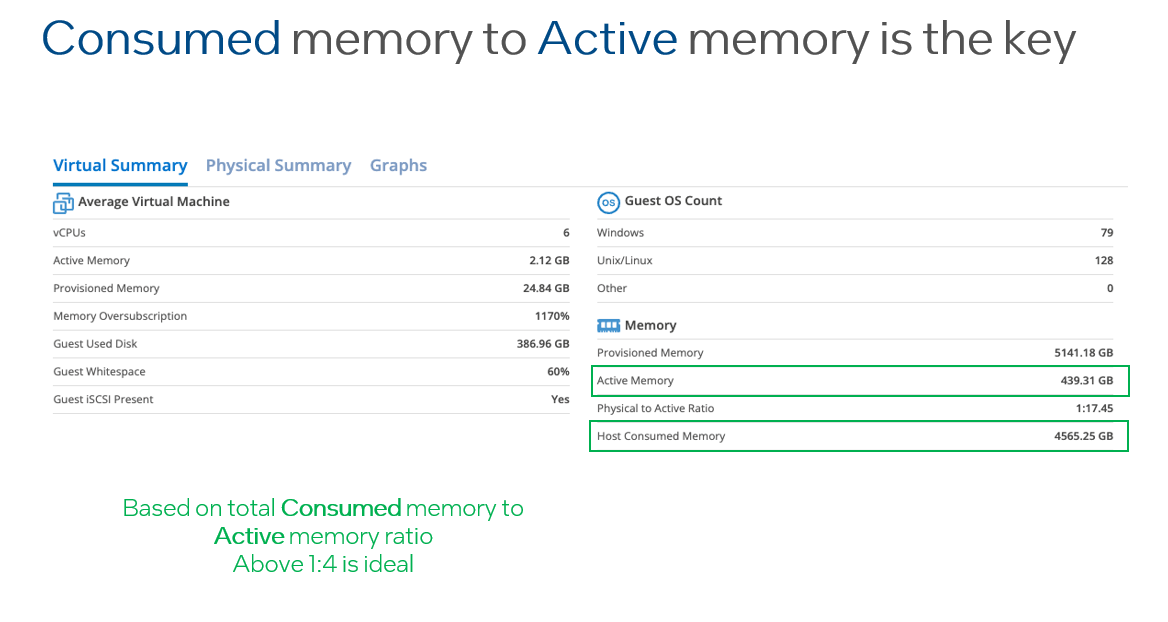
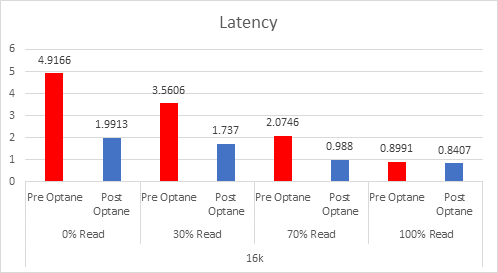
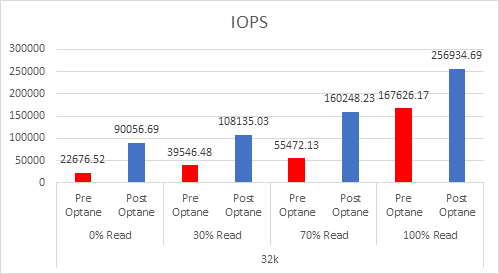
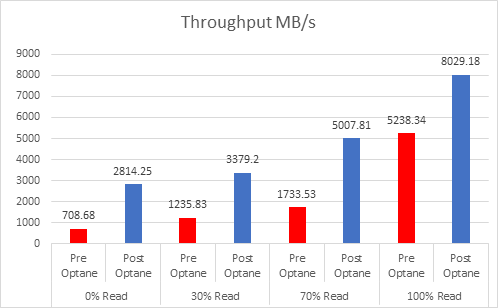
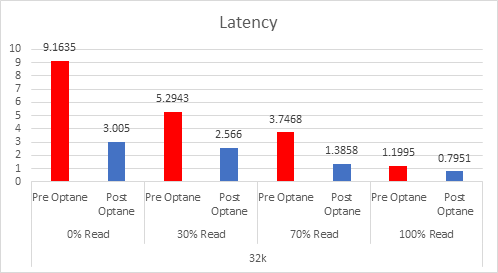
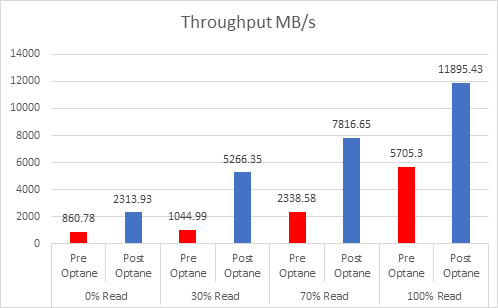
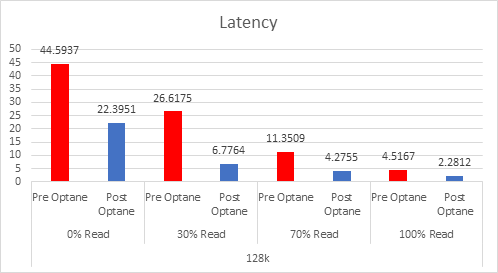
Providing your “Active” memory sits within the DRAM Cache, there should be very little to no performance impact, both Intel and VMware have done extensive testing on this.
Proof of Concepts
Nobody likes a PoC, they take up far too much of your valuable time, and time is valuable. I have worked with many customers where they have simply dropped in a memory tiering host into their existing all DRAM based cluster and migrated real workloads to the memory tiered host. This means no synthetic workloads, and the workloads you migrate to evaluate can simply be migrated back.
Conclusion
Optane is around for a few years yet, and even though it is going to go away eventually, the benefits of the technology are here today, in preparation for the architectures of the future based on CXL 2.0. Software designed to work with memory tiering will not change, it is the hardware and electronics that will change, so it protects the investment in software.
Optane technology is available from all the usual vendors, Dell, HPE, Cisco, Lenovo, Fujitsu, Supermicro are just a few, sometimes you may have to ask them for it, but as they say….”If you do not ask, you do not receive”.