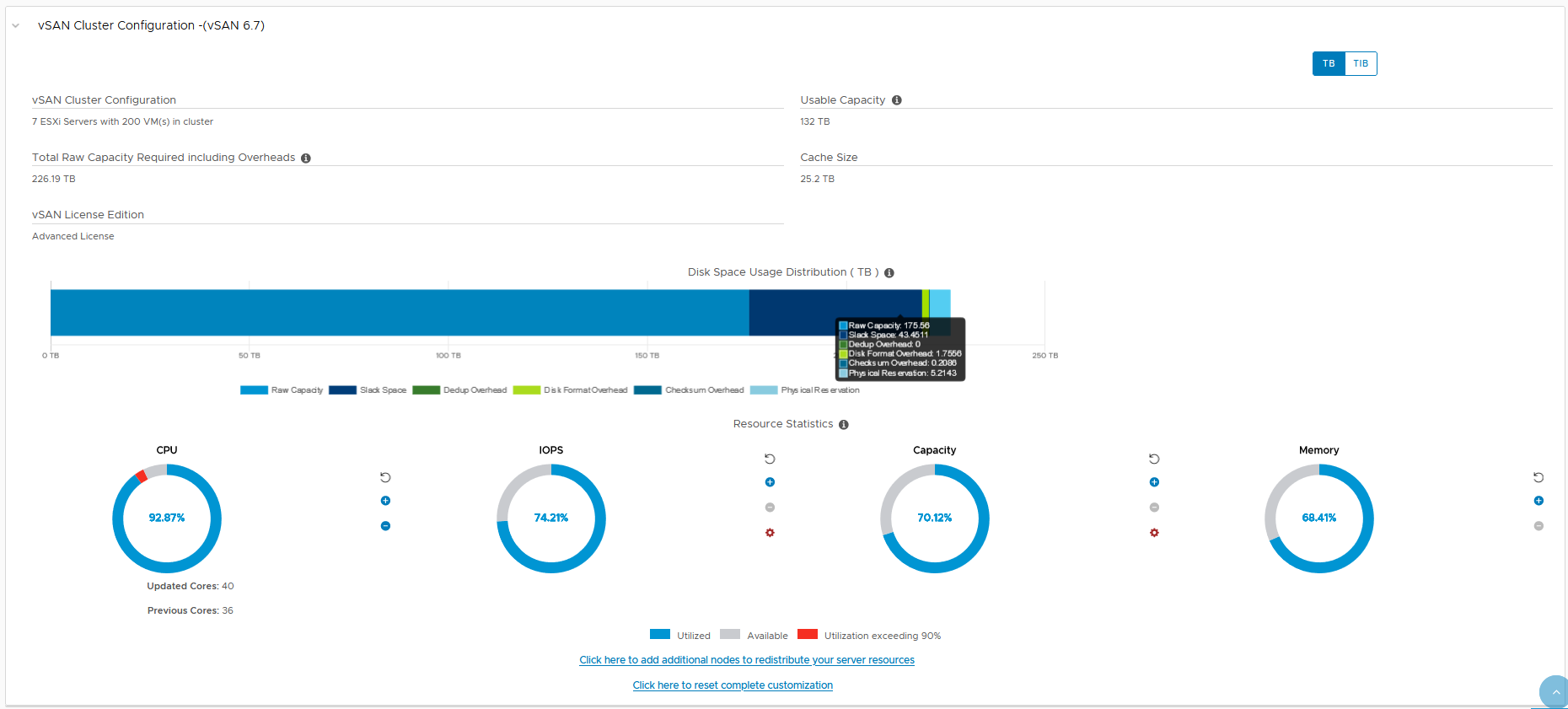
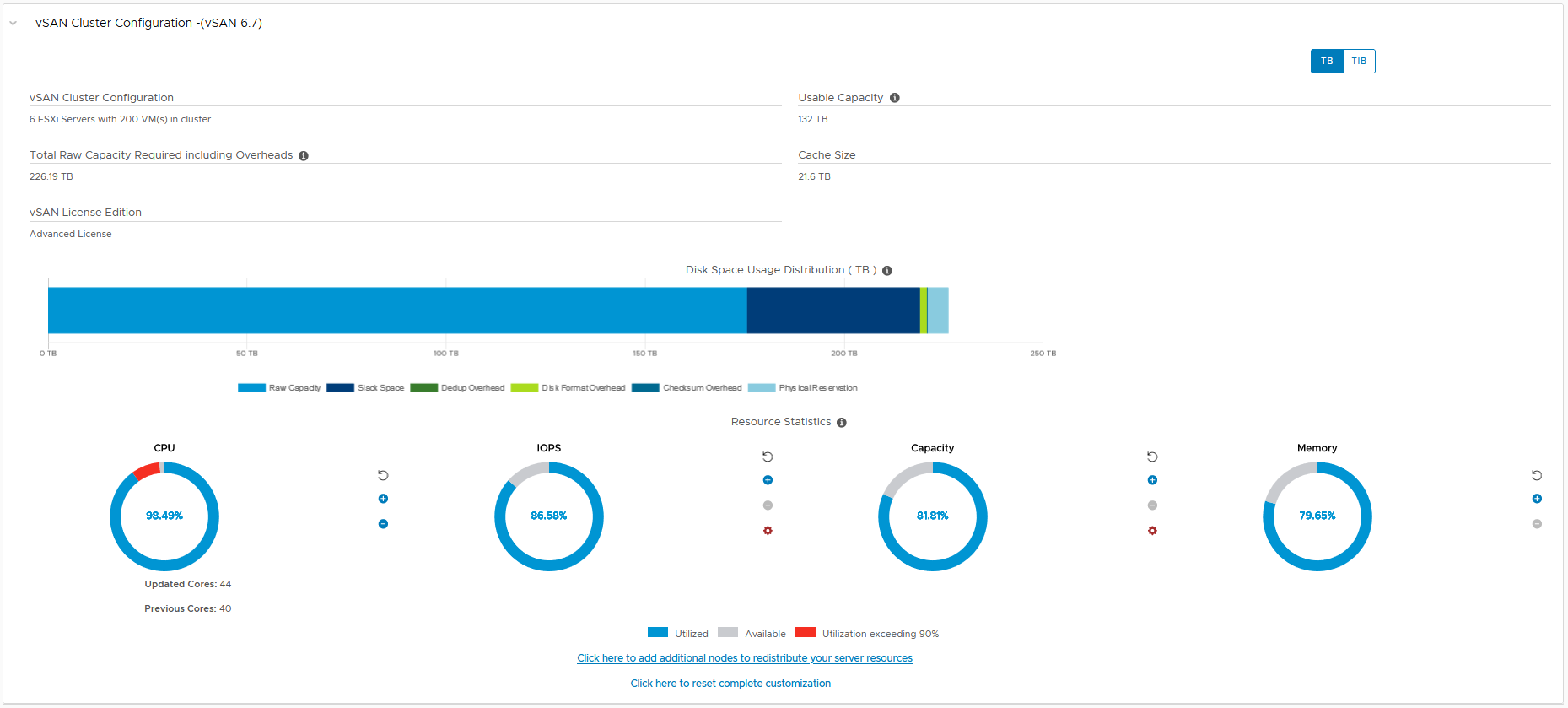
As we all know storage media has evolved very quickly over the past few years, the decline of the spinning disk and the move to flash based storage devices, but also the shift from SAS/SATA protocol based drives to NVMe protocol based drives in order to address the performance limitations of older protocols that were designed for spinning disks and not for SSDs.
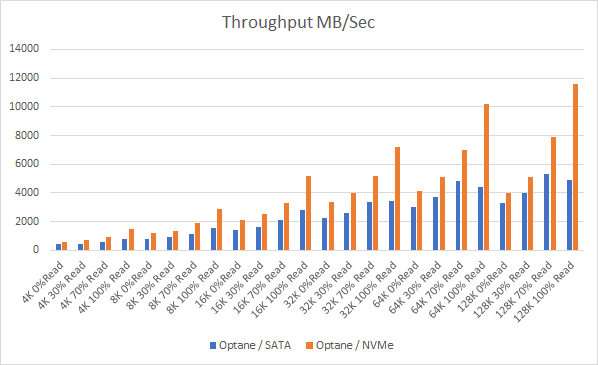
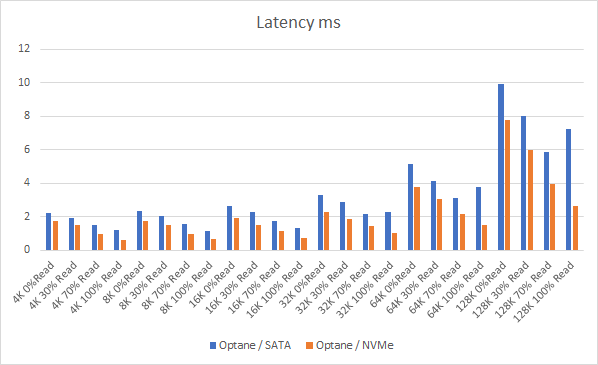
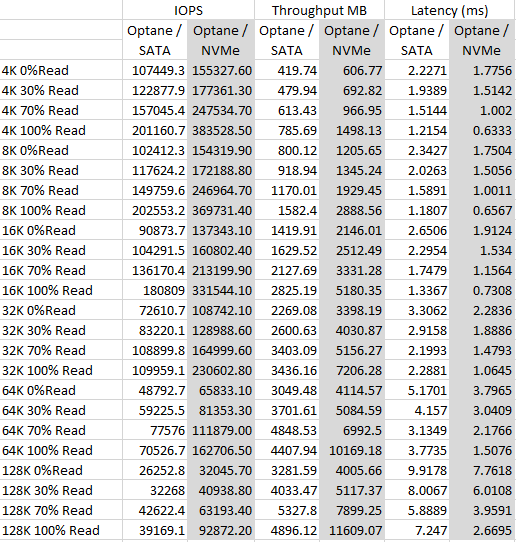
A question I get asked regularly is what type of SSD is best for the vSAN Cache tier, there are vSAN ready nodes out there that contain NAND based SSDs for both the cache tier and for the capacity tier, but then there are other technologies like Intel Optane™ SSDs being used for the cache tier, so let’s talk about the two, for the purpose of this comparison I am going to use the most common 3D NAND based NVMe in vSAN Ready node configurations, the 1.6TB Intel P4610 NVMe drive, and the 375GB P4800X Intel Optane™ SSD, both of these SSDs are NVMe based devices.
Let’s compare the two devices:
| 1.6TB Intel P4610 | 375GB P4800X Intel Optane™ P4800X | |
| Capacity | 1.6TB | 375GB |
| Sequential Read (up to) | 3200 MB/Sec | 2400 MB/Sec |
| Sequential Write (up to) | 2080 MB/Sec | 2000 MB/Sec |
| Random Read (100% Span) | 643000 IOPS | 550000 IOPS |
| Random Write (100% Span) | 199000 IOPS | 500000 IOPS |
| Latency Read | 77 µs | 10 µs |
| Latency Write | 18 µs | 10 µs |
| Endurance Rating | 12.25PBW or around 3.5 DWPD | Up to 60 DWPD or around 41PBW |
As you can see from the above table there are some major differences between the two different SSD’s notably the Random Write performance which is critical in the cache tier in a vSAN environment as all the incoming writes are random in nature and are absorbed by the cache tier, the NAND based SSD does not have as much capability around the random writes versus the Optane™ SSD, but the biggest impact to a vSAN Cache tier is the Drive Writes Per Day (DWPD), if you look at the specifications in detail, the P4610 can handle around 3.5 DWPD which equates to around 5.6TB of data written daily, whereas the 375GB Optane™ SSD can handle up to 60 DWPD which equates to 15TB of data written daily, remember that the Optane™ SSD is also less than a quarter of the capacity of the P4610, so in a vSAN environment cache tier, the Optane™ SSD wins hands down from an endurance perspective as well as the abaility to handle the random writes a lot quicker, so why such a difference?
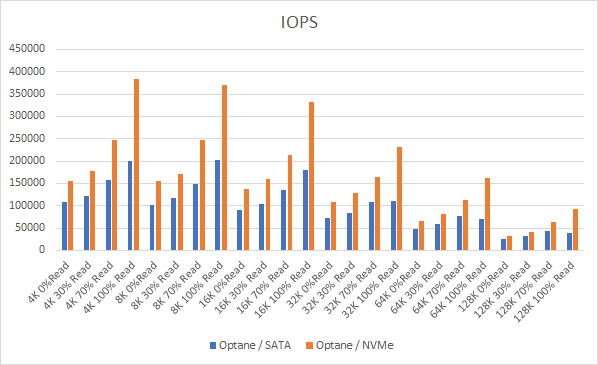
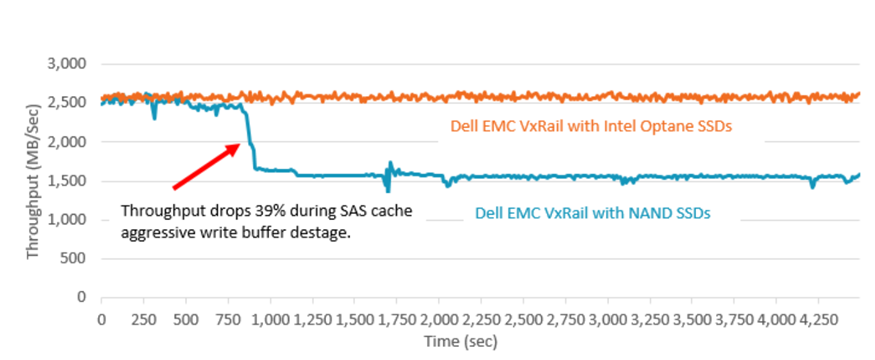
Well if you look at NAND based SSDs, firstly there is usally an element of DRAM that acts as a buffer to the NAND media which is usually around 1GB of DRAM for every TB of media, so any incoming writes hit the DRAM buffer first, this can be a positive boost in short, low block size write bursts, but cannot be sustained over a longer period of time, in an Optane™ SSD there is no such DRAM buffer so the data is being written to directly to the media. The VxRAIL team at Dell EMC have done some extensive testing around this and clearly demonstrated that a NAND based SSD cannot sustain the same level of write performance in a continuous fashion whereas the Optane™ SSD maintains the same level of write performance consistently, below is the results of their performance testing:
The way NAND based SSDs and Optane™ SSDs perfrom write operations is fundamentally different, in everybody’s NAND, media has to be read and written in pages, but everything has to be erased in blocks. Page updates are typically written to a new unused block, as new data is written, old pages become stale, and on an SSD these stale pages can build up fairly quickly which means at some point there a significant chunks of blocks that are obsolete, this then has to be garbage collected. This will then clear the block and allow that block to receive data, and the process starts all over again.
Optane™ SSDs are transistor-less which essentially means that each cell state can be changed from a 0 or 1 independently of other cells on the device. This means that Optane™ SSDs are completely bit addressable as opposed to having to write in pages, there is also no garbage collection required, and this obviously has a positive impact on performance as well as endurance which is why Optane™ SSDs have very high endurance capabilities.
So what does all this mean from an application perspective?
Well the VxRAIL Guys at Dell EMC also did some performance testing using Hammer DB and shown some significant performance gains when using Intel Optane™ SSDs versus traditional NAND as Cache as much as a 61% gain in performance in a complex OLTP workload

As we all know latency is critical in any type of workloads, what I have seen in performance testing is that Intel Optane™ SSDs consistently provide lower latency as well as a much more tightly controlled standard deviation on latency versus the P4610, even though in some smaller block size tests the performance of both devices was similar, in larger block size tests the Optane™ SSD again delivered lower latency and tightly controlled standard deviation in latency but also provided a much higher performance in comparison to the P4610. You also have to remember that the P4610 device was only using 37% Span due to vSAN Currently having a limit of 600GB write buffer per disk group, whereas the Optane™ SSD was using 100% Span, so the P4610 had a bit of an unfair advantage here.

Conclusion
What is clear from a vSAN perspective, endurance plays a critical role in the vSAN cache tier, in the very early days of vSAN there was no other choice but SAS or SATA based NAND devices with a ranging DWPD of between 10 and 25 based on an 800GB Drive, but as the technology evolution pushes the boundaries of performance and endurance, technology like Intel Optane™ SSDs clearly have an edge offering up to 60 DWPD on a smaller capacity of 375GB.
Smaller cache device…are you serious?
In the testing I have done on full NVMe systems where Intel Optane™ SSDs are being used in the vSAN Cache Tier, and standard more read-intensive NVMe drives like the Intel P4510 are being used in the capacity tier, a 375GB Optane™ SSD is more than sufficient, in most workloads a 750GB Optane™ SSD did not improve performance, even with 375GB I was only able to saturate the write buffer by 60% (based on vSAN 6.7 Update 3).
So whilst NAND based devices are fully supported as a vSAN cache device, they may not be the right choice when it comes down to consistent performance and endurance required for a modern infrastructure.