Sometimes during a deployment you might not be able to or want to install ESXi to the embedded SD Card controller on the Dell PowerEdge servers, for example if your memory configuration exceeds 512GB of RAM then installing ESXi to an SD Card would not be supported, or you may want to have a locally defined Scratch Partition on a local VMFS volume rather than using a remote Syslog or NFS Share, so what are the options?
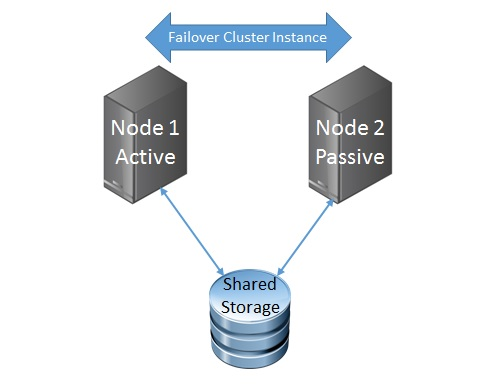
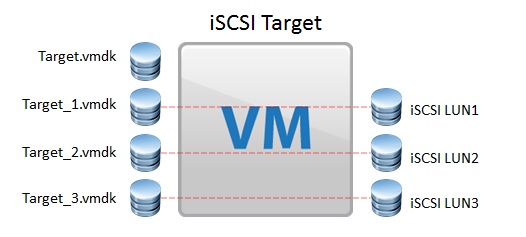
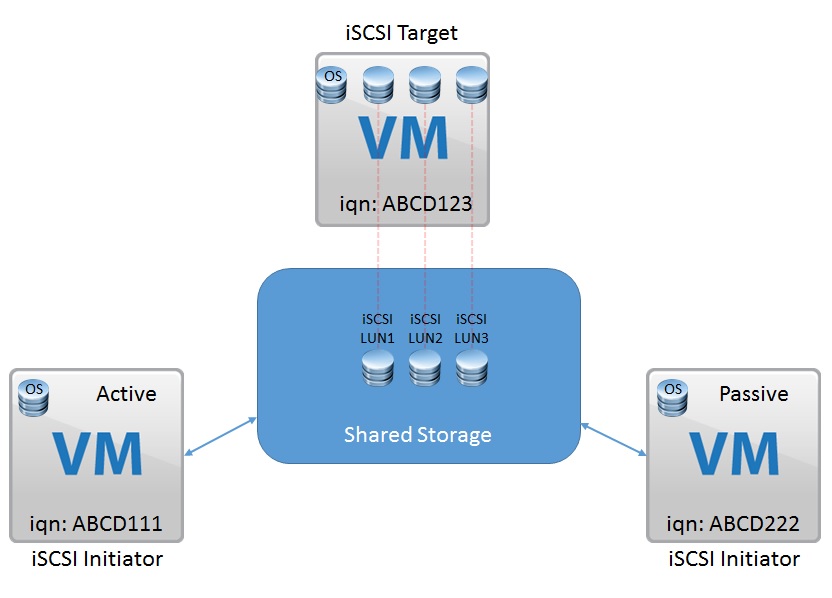
Well you could boot ESXi from a single disk, the downside to that is if the disk fails then you are in a host down situation, the other option is to use two disks in a RAID1 mirror and use that for the ESXi installation.? With servers such as the R730XD you can utilise all 24 drive slots in the front of the server for Virtual SAN, and then two rear 2.5 Inch slots for your RAID 1 Mirror drives.? In my lab environment I have a similar config, I have a bunch of SSD drives used by Virtual SAN and then two 300GB 10K SAS Drives in a RAID 1 Mirror for my ESXi install and local VMFS Volume.? So how do we configure the H730 controller to support both Passthrough Disks and RAID disks?
Please note: For production environments this type of configuration is not supported
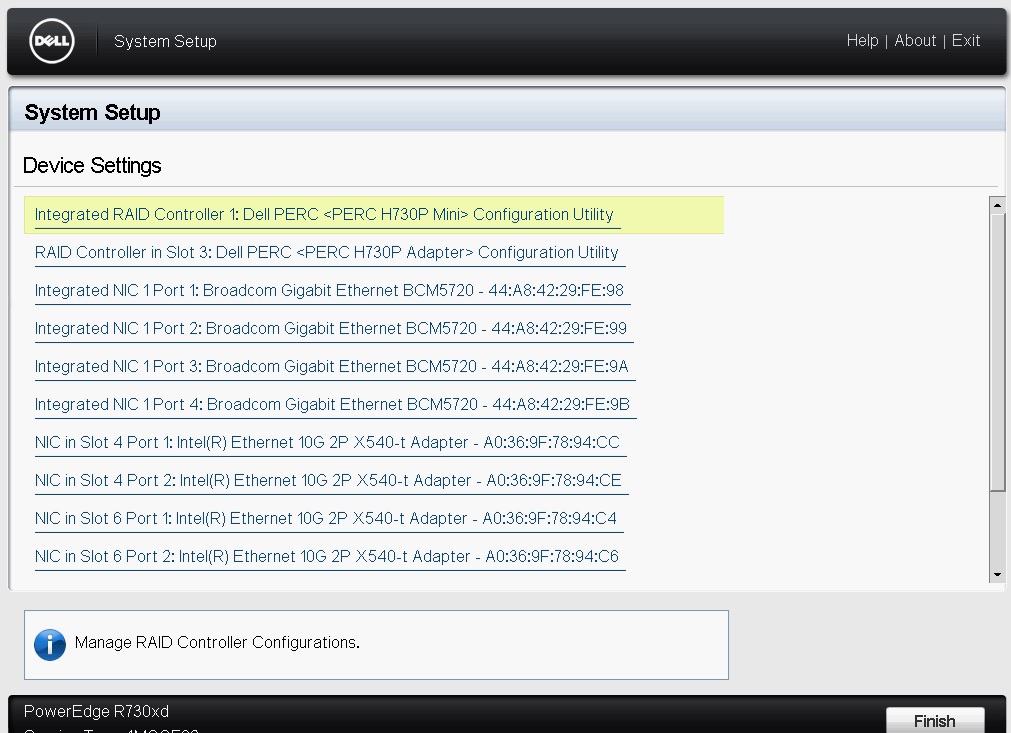
The first thing we need to do is ensure that the controller itself is configured for RAID Mode, for those that do not know, the H730 controller can be configured in either RAID Mode or HBA Mode.? RAID Mode allows you to create RAID Virtual Disks to be handled by the Logical Disk Controller as part of a RAID Volume, it also allows you to configure physical disks as NON-RAID disks, HBA Mode allows you to configure disks as NON-RAID capable only, in order to set the controller as RAID Mode we need to enter the System Setup Screen, to do this reboot the host and press F2 to enter the System Setup Main Menu, once there we need to enter the Device Settings option
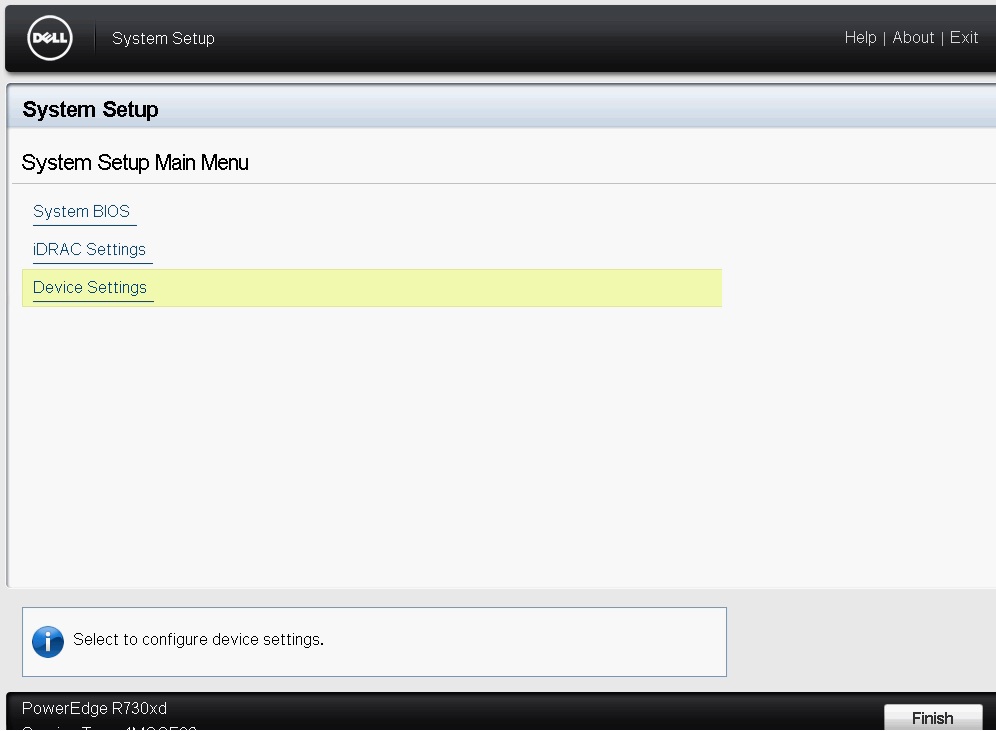
This section of the System Setup will allow you to change the settings for any devices connected in the system, for the purpose of this article we will be focusing on the PERC H730 controller, in my servers I have two controllers, so I am selecting the one that is second in the list labelled RAID Controller in Slot 3: Dell PERC <PERC H730P Adapter> Configuration Utility
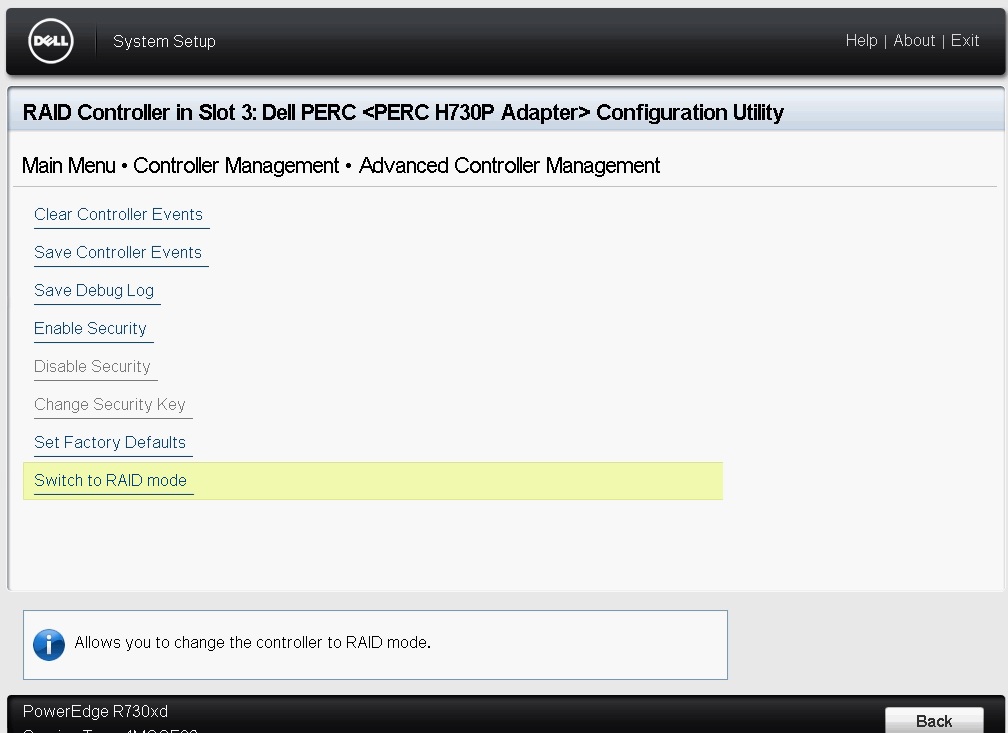
Once in the Device settings we need to chose the option for Controller Management and at the way to the bottom and choose the option for Advanced Controller Management, in there you will see an option for Switch to RAID Mode, when selected it will inform you that a reboot is required, do not reboot the host just yet.
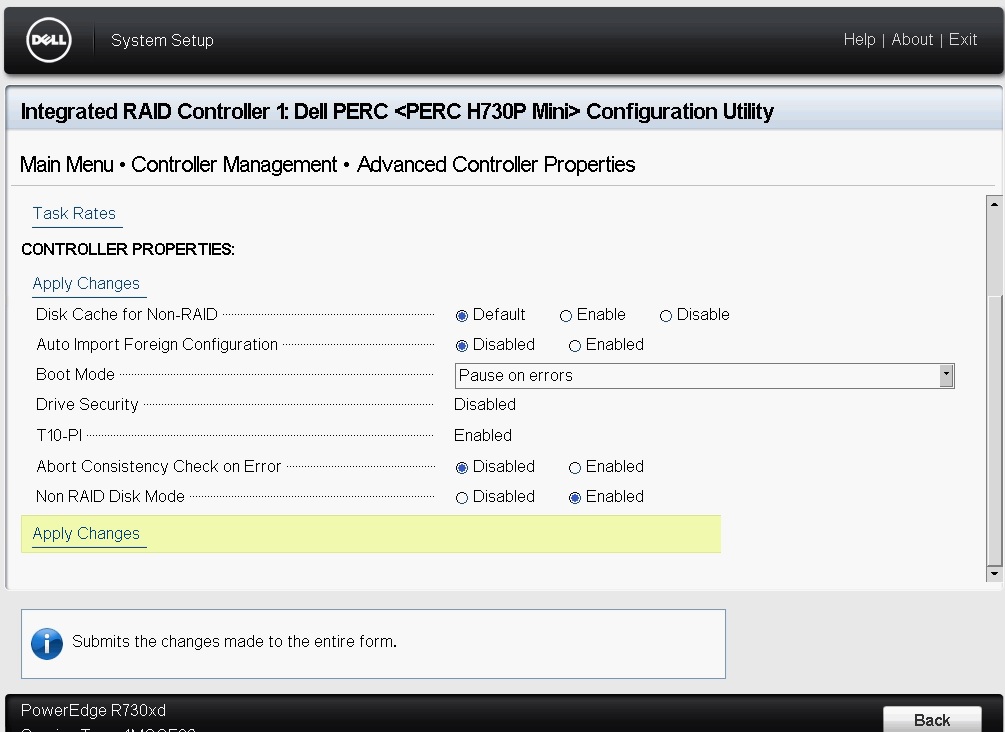
Now we need to ensure that NON-RAID Disk Mode is enabled, for this, click on Back and enter the Advanced Controller Properties at the bottom of the screen and select the option to enable for Non RAID Disk Mode and hit Apply Changed
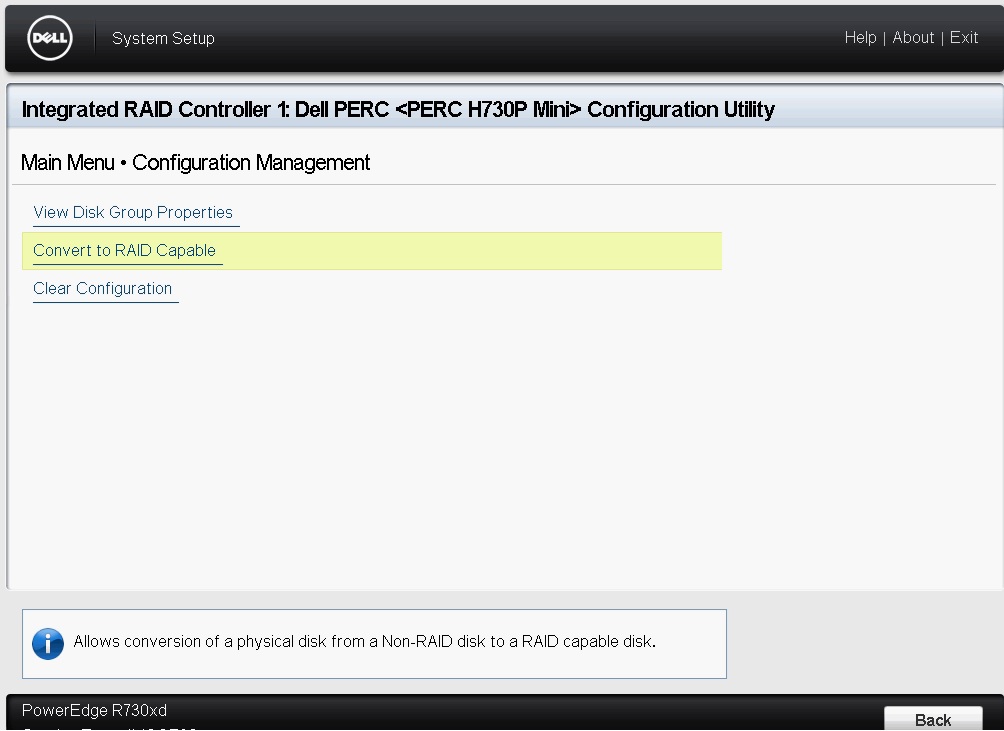
At this point you will need to make the disks you wish to use as a RAID1 as RAID Capable, you can do this under Configuration Management and choose the option to Convert to RAID Capable, from within here select the two disks you wish to use as your RAID 1 and click on OK, check the Confirm box and click on yes to confirm
Click on Back to go to the main menu and then re-select Configuration Management and chose the option to Create Virtual Disk and proceed to create your RAID 1 disk, it will only let you select disks that have been switched to RAID capable, after completion, check that all other disks are seen as NON-RAID Disks under Physical Disk Management, since we switched the controller from HBA Mode to RAID Mode all the other disks should still be tagged as NON-RAID
Now your PERC H730 controller is configured for both RAID and Passthrough and your RAID1 Virtual Disk can be used to install your ESXi, during the ESXi installation, make sure you install to the correct disk, and all your other disks are passthrough mode and can be consumed by Virtual SAN
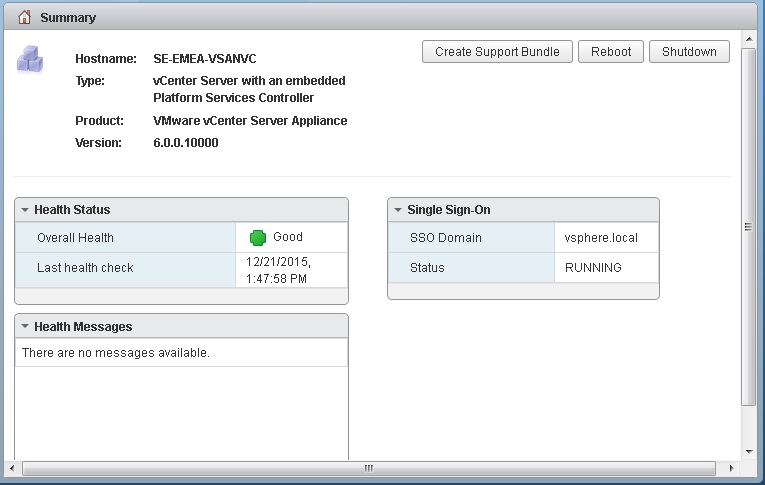 Step 2 – Powering down the Virtual Center Server
Step 2 – Powering down the Virtual Center Server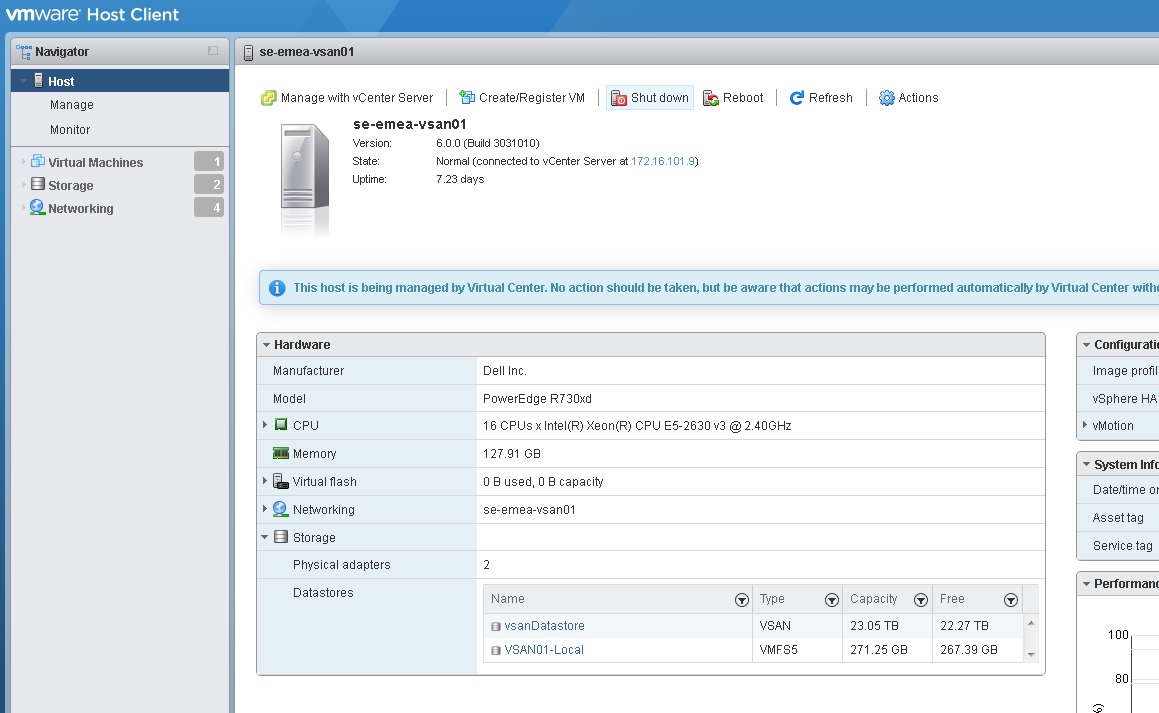 One of the other options and I would highly recommend this option is the VMware Host Client, this is basically a vib you install on each of your hosts, and then you point your web browser to the IP address or FQDN with a “/ui” at the end, this will bring you to a host based web client that is fantastic to use for managing an ESXi host outside of vCenter, from within this client you can place the host into maintenance mode from the Actions tab, and also shut the host down from the same tab.
One of the other options and I would highly recommend this option is the VMware Host Client, this is basically a vib you install on each of your hosts, and then you point your web browser to the IP address or FQDN with a “/ui” at the end, this will bring you to a host based web client that is fantastic to use for managing an ESXi host outside of vCenter, from within this client you can place the host into maintenance mode from the Actions tab, and also shut the host down from the same tab.